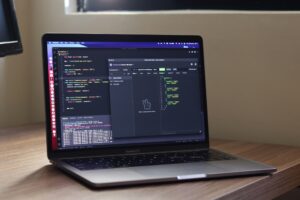
VLLM с открытым исходным кодом представляет собой веху в технологии обслуживания крупной языковой модели (LLM), предоставляя разработчикам быстрый, гибкий и готовый к производству механизм вывода.
Первоначально разработанная в лаборатории Sky Computing в UC Berkeley, эта библиотека превратилась в проект, управляемый сообществом, который решает критические проблемы управления памятью, оптимизацию пропускной способности и масштабируемое развертывание в приложениях LLM. Инновационный подход библиотеки к механизмам внимания и распределению памяти установил его как ведущее решение для организаций, стремящихся эффективно развернуть LLMS в масштабе.
Быстрый рост VLLM как основополагающей технологии в экосистеме вывода искусственного интеллекта сильно поддерживается крупными игроками отрасли, особенно Red Hat. Red Hat имеет интегрированную VLLM в основе сервера вывода AI, основанного на OpenShift. Интеграция между OpenShift и VLLM осуществляется с помощью модельной платформы OpenShift Model AI, которая использует Kserve для развертывания и управления моделями ИИ в масштабе.
LLM-D, проект с открытым исходным кодом, недавно выпущенный Google и Red Hat, оснащен высокоэффективным двигателем вывода VLLM, позволяющий распределенным, Kubernetes-Com-Contive LLM в масштабе.
Основная архитектура и ключевые характеристики механизм гипсуата
Краеугольный камень преимущества VLLM в области производительности заключается в его алгоритме Pagegatationation, который принципиально переосмысливает, как память с ключевым значением (KV) управляется во время вывода. В отличие от традиционных подходов, которые выделяют смежные блоки памяти, Pagegatattureation разделяет KV-кэш на блоки с фиксированным размером, которые можно хранить в непрерывных местах памяти. Эта конструкция, вдохновленная методами виртуальной памяти операционной системы, обеспечивает эффективное обмен памятью и значительно снижает фрагментацию.
Система Pagegatattureation поддерживает блок -таблицы, которые отображают логические блоки KV с блоками физической памяти для каждого запроса, обеспечивая гибкость при распределении памяти, обеспечивая при этом оптимальное использование графического процессора. При обработке последовательностей алгоритм вычисляет оценки внимания с использованием блочного подхода, разделяющих ключевые и значения векторов на блоки с фиксированным размером для эффективного управления памятью и вычислений. Этот подход позволяет VLLM обрабатывать динамические длины последовательности без отходов памяти, связанных с традиционными методами прокладки.
Непрерывное партии и динамическое планирование
VLLM реализует непрерывное количество партии, также известное как динамическое планирование и итерационное уровни, которое работает на гранулярности шагов отдельных генераций, а не целых последовательностей. Этот подход устраняет проблему блокировки головы линии, присущей статической партийной системам, где запросы быстро заполняются, которые должны ждать более медленных. Система сохраняет очередь запроса и динамически сочетает партии на каждом прямом проходе, добавляя новые запросы в в настоящее время запущенные партии, когда позволяет емкость.
Механизм непрерывного партии предлагает несколько важных преимуществ, включая увеличение пропускной способности за счет постоянного использования графических процессоров, снижение средней задержки при обработке запросов и улучшено использование ресурсов путем минимизации времени холостого хода. Когда последовательности завершают генерацию, их ресурсы немедленно освобождаются и предоставляются для новых запросов на следующем этапе обработки.
Усовершенствованные функции оптимизации
VLLM включает в себя несколько методов оптимизации, которые повышают производительность в различных сценариях развертывания, включая процессоры и графические процессоры. Система поддерживает различные методы квантования, включая GPTQ, AWQ, Int4, Int8 и FP8, что обеспечивает эффективное развертывание в средах с ограниченными ресурсами. Спекулятивные возможности декодирования позволяют системе проактивно генерировать потенциальные будущие токены, снижая задержку в интерактивных приложениях.
Библиотека реализует функциональные возможности предварительной засыпки, которая обеспечивает эффективную обработку длинных входных последовательностей, разбивая их на управляемые куски. Эта функция особенно полезна для приложений, требующих обширных контекстов или возможностей обработки документов. Кроме того, VLLM поддерживает оптимизированные ядра CUDA путем интеграции Flashattention и Flashinfer, обеспечивая оптимизацию для аппаратного обеспечения для максимальной производительности.
Совместимость модели и поддерживаемая поддержка архитектуры модели
VLLM обеспечивает обширную совместимость с популярными модельными архитектурами посредством бесшовной интеграции с обнимающими трансформаторами лица. Система поддерживает генеративные и объединяющие модели по различным задачам, когда пользователи могут указать задачу с помощью аргументов командной строки. Для моделей, не поддерживаемых, VLLM предлагает совместимость через бэкэнд трансформаторов, что позволяет использовать пользовательские модели, прежде чем они получат официальную поддержку.
Библиотека поддерживает широкую поддержку языковых моделей, основанных на декодере, с постоянным развитием возможностей модели на языке зрения. Пользовательская модель интеграция облегчена с помощью хорошо документированных API, которые позволяют разработчикам расширить функциональность VLLM для специализированных архитектур. Система автоматически обнаруживает совместимые модели и может при необходимости использовать конкретные реализации.
Поддержка аппаратной платформы
Аппаратная совместимость VLLM охватывает несколько поставщиков и архитектуры, поддерживая графические процессоры NVIDIA, процессоры AMD и графические процессоры, процессоры Intel, акселераторы Gaudi, процессоры IBM Power, TPU и AWS Tradium и Unferentia Accelerators. Матрица совместимости квантования демонстрирует комплексную поддержку на аппаратных платформах, хотя некоторые методы оптимизированы для конкретных поколений графических процессоров.
GPU NVIDIA варьируется от старых архитектур Volta до последних систем бункеров, с различными методами квантования, оптимизированными для конкретных вычислений. Поддержка GPU AMD включает в себя совместимость с современными архитектурами RDNA, в то время как поддержка GPU Intel предоставляет варианты для различных сред. Эта широкая совместимость аппаратного обеспечения позволяет организациям использовать существующую инфраструктуру, сохраняя при этом оптимальные характеристики производительности.
Параметры развертывания и развертывание контейнеров на основе интеграции
VLLM предлагает комплексную поддержку Docker через официальные изображения контейнеров, доступные на Docker Hub. Основное изображение контейнера, VLLM/VLLM-Openai, предоставляет полную среду, совместимуе с OpenAI, которую можно развернуть на различных платформах оркестровки контейнеров. Развертывание контейнера поддерживает ускорение графического процессора во время выполнения контейнера nvidia, с надлежащей конфигурацией общей памяти для тензора параллельных операций.
Пользовательские сборки контейнеров поддерживаются для организаций, требующих конкретных зависимостей или конфигураций. Изображения Docker могут быть расширены с помощью дополнительных слоев для удовлетворения специализированных требований, таких как возможности обработки аудио или версии трансформаторов разработки. Развертывание контейнеров упрощает процесс перехода от разработки к производственной среде, сохраняя при этом согласованность в разных целях развертывания.
Kubernetes и производственное оркестров
Развертывание Kubernetes полностью поддерживается посредством комплексных конфигураций YAML и диаграмм Helm. Процесс развертывания требует плагина устройства NVIDIA Kubernetes для управления ресурсами графического процессора и надлежащей постоянной конфигурации громкости для кэширования модели. Интеграция VLLM Kubernetes поддерживает горизонтальное масштабирование через управление репликами и обнаружение услуг через стандартную сеть Kubernetes.
Производительный стек VLLM предлагает возможности развертывания корпоративного уровня, включая совместимость вверх по течению, упрощенное развертывание с помощью диаграмм Helm и интегрированной наблюдаемости через панели панели Grafana. Этот подход, ориентированный на производство, включает в себя такие функции, как поддержка мультимодели, маршрутизацию модели, быстрое начальное начало и возможности разгрузки кэша KV. Производительный стек предназначен для рабочих нагрузок LLM с оптимизацией для высокопроизводительных сценариев.
Совместимость и интеграция API
VLLM предоставляет HTTP-сервер, совместимый с OpenAI, который реализует стандартные завершения и API чата, что обеспечивает бесшовную интеграцию с существующими приложениями. Сервер поддерживает все основные конечные точки API OpenAI, включая завершения, завершения чата, встраивания и аудиопроводки, с дополнительными пользовательскими конечными точками для токенизации, объединения и оценки. Дополнительные параметры за пределами спецификации OpenaI могут быть переданы через параметр Extra_body для расширенной функциональности.
API-сервер поддерживает потоковые ответы для приложений в реальном времени, с генерацией выводов с токеном, которая улучшает пользовательский опыт в интерактивных сценариях. Аутентификация обрабатывается с помощью клавиш API, а сервер может быть настроен с различными специфичными для модели параметров, включая конфигурации генерации и параметры отбора проб. Интеграция с популярными клиентами HTTP и официальной библиотекой Python Openai является простым и хорошо документированным.
VLLM зарекомендовал себя как преобразующая технология в ландшафте вывода LLM, предоставляя разработчикам необходимые инструменты для развертывания высокопроизводительных языковых моделей в масштабе. Его инновационный механизм Pageartattureation и непрерывные возможности партии решают фундаментальные проблемы в области управления памятью и оптимизации пропускной способности. Комплексная аппаратная поддержка, гибкие варианты развертывания и совместимый с API OpenAI делают VLLM идеальным выбором для организаций, стремящихся внедрить услуги LLM производственного уровня.
Активное развитие библиотеки и подход, управляемый сообществом, обеспечивает постоянные инновации и адаптацию к возникающим требованиям в быстро развивающемся ландшафте ИИ. Благодаря его проверенным преимуществам эффективности и надежным набором функций, VLLM представляет стратегические инвестиции для разработчиков, создающих следующее поколение приложений, работающих на AI.
В следующей части этой серии я сделаю глубокое погружение в основные возможности и конференции по выводу VLLM. Следите за обновлениями.
Trending Stories youtube.com/thenewstack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Janakiram MSV является основным аналитиком в Janakiram & Associates и адъюнкт -преподавателем Международного института информационных технологий. Он также является квалифицированным Google Cloud Developer, сертифицированным архитектором решений Amazon, сертифицированным разработчиком Amazon, … Подробнее от Janakiram MSV