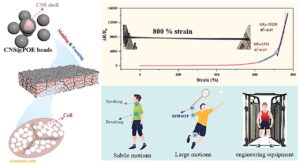
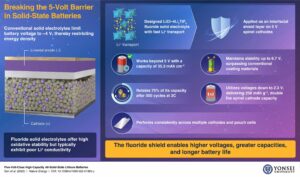
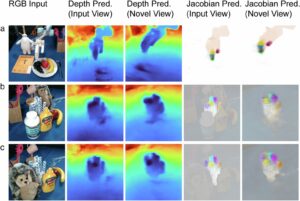
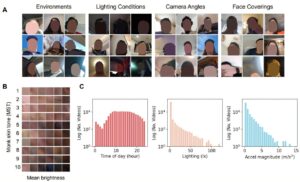
Pagerduty спонсировал этот пост.
Как идет клише: мусор, мусор. Это относится непосредственно к системам AI.
Если данные, попадающие в систему, являются неточными или неполными, то выводы из этих данных будут ошибочными.
Это то же самое с разнообразием данных. Если система ИИ видит только ограниченное подмножество среды, она в конечном итоге предвзято. Он не сделает сильные выводы об остальной части системы, потому что примеры, на которых она учится, не представляют полную картину.
Это особенно верно в управлении инцидентами. Когда вы можете эффективно собирать данные об инцидентах, вы можете начать строить корреляции между различными атрибутами, получая сильное понимание инцидентных нюансов, и именно здесь ИИ действительно становится ценным.
360-градусный вид на ландшафт инцидента
Есть много факторов, которые информируют о природе инцидента и о том, как его следует разрешить.
Например, интеграция источника дает вам подсказки о влиятельной системе. Окружающая среда рассказывает вам, насколько это важно, будь то тестовая система или производственная среда. Даже время инцидентов имеет значение. Если инцидент происходит сразу после другого, команды могут использовать его в качестве сигнала, чтобы определить, является ли он частью шаблона или изолированной проблемы.
Тогда есть сторона разрешения. автоматизация, используемая для диагностики или исправления инцидента, невероятно поучительна. У вас также есть источники, такие как обновления статуса и заметки об инцидентах, которые часто объясняют, почему возникла проблема или как она была решена.
Когда у вас есть как глубокие, так и широкие данные, вы можете нарисовать полную картину 360-градусного ландшафта или даже более широкий технологический ландшафт. В основном есть два больших ведра атрибутов, которые можно посмотреть: как происходят инциденты и как они решаются.
Чем больше видимости система ИИ обладает по этим атрибутам, тем более мощной она становится. Он может гибко классифицировать инциденты наряду с похожими и определить гораздо более сильную стратегию разрешения. Такая гибкость делает систему надежной.
Как выглядят сильные данные об инцидентах
Как правило, вам нужно два типа данных:
- Данные об происхождении инцидента: Данные, которые дают представление о том, какая система была затронута, окружающая среда, в которой правило вызвало оповещение, его временную метку и затронутую службу.
- Данные разрешения инцидентов: Данные, которые показывают, какая автоматизация была запущена, аннотации пользователей, такие как заметки или обновления статуса, Slack Cantrations и Zoom Transcripts.
Вместе данные об происхождении инцидента и разрешении рисуют богатый 360-градусный профиль инцидента. Полная картина помогает убедиться, что инциденты имеют категорию правильно. После категории стратегии исторического разрешения могут быть всплывают или даже выполнены автоматически с использованием агентского ИИ, для ускорения ответа.
Когда ИИ может с уверенностью сцеплять инциденты команды, он часто сокращает шум и ускоряет разрешение. Представьте, что инциденты команды могут быть сгруппированы в тип A, который можно игнорировать, тип B, который просто нуждается в автоматизации и типе C, который требует вмешательства человека. Тип С становится основным направлением. Управление инцидентами таким образом помогает командам масштабироваться по мере роста их технических стеков, без роста объема инцидентов с той же скоростью.
Скорость и уверенность с помощью автоматизации
Допустим, команда создала сценарии для выполнения диагностики или действий по восстановлению. Когда происходит инцидент, респонденты могут нажать кнопку, запустить автоматизацию и увидеть результаты. Но эти автоматизации часто пишут разработчиками, и новые респонденты могут не знать, какие использовать или как.
Вот где ИИ может быть действительно полезным. Система рассматривает доступные автоматизации и теги наиболее полезными для этого конкретного инцидента, и в рамках этого рекомендованного набора она расставляет приоритеты в действии, которое респондент должен предпринять в первую очередь. Респонденты, которые не знакомы с доступной автоматизацией, могут затем выбрать правильное действие быстрее и с большей уверенностью.
От данных, обработанного до производства данных
Предприятия всегда использовали данные для информирования о решениях, но сейчас, и в ближайшем будущем произойдет переход к тому, где данные не будут просто информировать решения. Это произведет их.
С ростом агентского ИИ систем начинают обладать реальной автономией. Эти агенты уже отсутствуют в мире, принимая решения, и решения, которые они принимают, полностью информированы по данным, которые они предоставлены. Данные переходят от консультанта на заднем сиденье к сидям на переднем сиденье, вождение.
Это большой сдвиг, и это означает, что компании должны будут убедиться, что данные, которые они используют, для поддержки своих клиентов, а также для работы в этих системах принятия решений, являются каменными и высокими качеством.
Создание правильного фонда: управление данными
Лучший способ обеспечить правильные данные — правильные решения — это наращивать сильные мышцы вокруг управления данными. Есть несколько ключевых столбов:
- Целостность данных: Убедитесь, что данные чистые, точные и стандартизированные. Используйте согласованные форматы и соглашения об именах. Строительными мониторами, которые могут сообщить о оценках качества данных, чтобы провести непрерывное осмотр здоровья данных.
- Безопасность данных: Установите доверие медленно, но теряйте его сразу. Данные должны контролироваться и шифровать, где это возможно. Создайте аудиторские отчеты, которые входят в систему, кто получил доступ к данным и когда, и настройте оповещения.
- Согласие: Организации должны соблюдать правила на рынках, на которых вы работаете, но также думать заранее. Даже если в настоящее время не активно участвует в ЕС, стоит подготовиться к GDPR или Закону ЕС AI, чтобы организация была готова к расширению.
- Хранилище: Затраты на хранение данных могут быстро. В мире, где организации собирают все больше и больше данных, стоит эффективно избегать ненужных накладных расходов.
Итог: системы, принимающие решения завтра, обучаются данным, которыми вы управляете сегодня.
Pagerduty является глобальным лидером в области управления цифровыми операциями, преобразующий критическую работу для современных предприятий. PageRduty Operations Cloud объединяет AIOP, автоматизацию, операции обслуживания клиентов и управление инцидентами для создания гибкой, устойчивой и масштабируемой платформы. Узнайте больше последних из Pagerduty Trending Stories YouTube.com/thenewstack Tech, быстро движется, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Скотт Бастек — старший прикладной ученый в Pagerduty. Он имеет большой опыт работы в области ИИ и аналитики данных. В настоящее время он сосредоточен на создании функциональности ИИ, ориентированной на клиента, в Pagerduty. Базируясь в Лиссабоне, Скотт разбивает свое время, сидя в киосках и … Подробнее от Скотта Бастека