Кредит: Вашингтонский университет
Туочао Чен, докторант Вашингтонского университета, недавно совершил поездку по музею в Мексике. Чен не говорит по -испански, поэтому он запустил приложение для перевода на своем телефоне и направил микрофон на гид. Но даже в относительной тишине музея окружающий шум был слишком большим. Полученный текст был бесполезен.
В последнее время появились различные технологии, многообещающие бегливые переводы, но ни одна из этих решений проблемы общественного пространства Чена. Например, новые очки Meta функционируют только с изолированным динамиком; Они играют автоматический голосовой перевод после того, как динамик закончится.
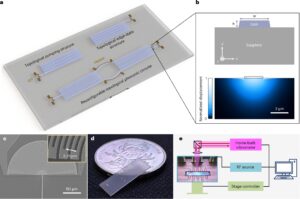
Теперь Чен и команда исследователей UW разработали систему наушников, которая переводит несколько динамиков одновременно, сохраняя при этом направление и качества голосов людей. Команда построила систему, называемую трансляцией пространственной речи, с готовыми наушниками с шумоподавлением, оснащенными микрофонами. Алгоритмы команды разделяют различные ораторы в пространстве и следуют за ними, когда они движутся, переводят свою речь и воспроизводят ее с задержкой 2-4 секунды.
Университет Вашингтона исследователи разработали систему наушников, которая переводит нескольких человек, говорящих одновременно, следуя за ними, когда они движутся и сохраняя направление и качества своих голосов. Команда построила систему, называемую трансляцией пространственной речи, с готовыми наушниками с шумоподавлением, оснащенными микрофонами. Кредит: Chen et al./chi ’25
Команда представила свое исследование 30 апреля на конференции ACM CHI по человеческим факторам в вычислительных системах в Йокогаме, Япония. Код для устройства проверки концепции доступен для других. «Другая технология перевода основана на предположении, что говорит только один человек», — сказал старший автор Шьям Голлакота, профессор UW в Школе компьютерных наук и инженерии Пола Г. Аллена. «Но в реальном мире у вас не может быть только одного роботизированного голоса, говорящего для нескольких людей в комнате. Впервые мы сохранили звук голоса каждого человека и направления, от которого он исходит».
Система делает три инновации. Во -первых, при включении, он сразу обнаруживает, сколько динамиков находится в помещении или на открытом воздухе.
«Наши алгоритмы работают немного как радар», — сказал ведущий автор Чен, докторский ученик UW в школе Аллена. «Таким образом, они сканируют пространство в 360 градусах и постоянно определяют и обновляют, есть ли один человек, шесть или семь».
Затем система переводит речь и поддерживает выразительные качества и объем голоса каждого динамика во время работы на устройстве, таких как мобильные устройства с чипом Apple M2, такими как ноутбуки и Apple Vision Pro. (Команда избегала использования облачных вычислений из -за проблем с конфиденциальностью с голосовым клонированием.) Наконец, когда ораторы перемещают головы, система продолжает отслеживать направление и качества своих голосов по мере их изменения.
Система функционировала при тестировании в 10 внутренних и наружных настройках. А в тесте с 29 участниками пользователи предпочитали систему, а не модели, которые не отслеживали динамики через пространство.
В отдельном пользовательском тесте большинство участников предпочитали задержку 3-4 секунды, поскольку система допустила больше ошибок при переводе с задержкой 1-2 секунды. Команда работает над снижением скорости перевода в будущих итерациях. В настоящее время система работает только на обычной речи, а не на специализированном языке, такой как технический жаргон. Для этой статьи команда работала с испанским, немецким и французским языком, но предыдущая работа над моделями перевода показала, что их можно обучить переводить около 100 языков.
«Это шаг к преодолению языковых барьеров между культурами», — сказал Чен. «Так что, если я иду по улице в Мексике, хотя я не говорю по -испански, я могу перевести все голоса людей и узнать, кто что сказал».
Qirui Wang, стажер исследований в Hydrox AI и бакалавриат UW в школе Аллена, заканчивая это исследование, и Runlin He, докторант UW в школе Аллена, также являются соавторами в этой статье.
Больше информации:
Tuochao Chen et al. Труды конференции Чи 2025 года по человеческим факторам в вычислительных системах (2025). Doi: 10.1145/3706598.3713745
Предоставлено Университетом Вашингтона
Цитирование: Наушники с AI предлагают групповой перевод с голосовым клонированием, а 3D-пространственный аудио (2025, 10 мая) Получено 12 мая 2025 года из этого документа подлежит авторским правам. Помимо каких -либо справедливых сделок с целью частного исследования или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Контент предоставляется только для информационных целей.