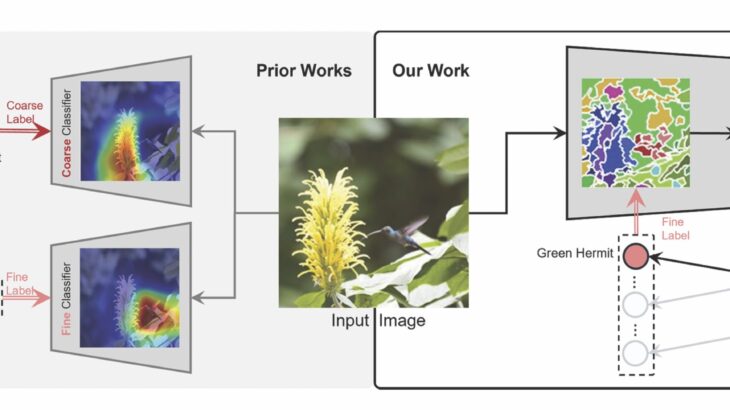
Новая модель компьютерного зрения, H-CAST, выравнивает грубые и мелкозернистые классификаторы с использованием сегментации внутриимнового изображения. Предыдущие модели рассматривают тонкие и грубые уровни как отдельные задачи, что приводит к ошибкам, когда тонкий классификатор предсказывает виды птиц, в то время как грубый классификатор предсказывает «растение». Кредит: Park et al., 2025
Новая модель искусственного интеллекта, H-CAST, группируют подробности в концепции на уровне объектов, когда внимание движется от нижних к высоким уровням, выводя дерево классификации-например, птица, орел, белоголовый орлл-а не фокусируясь только на мелкозернистом распознавании.
Исследование было представлено на Международной конференции по обучению в Сингапуре и основано на предыдущей модели команды, созданном в роли для визуально обоснованной одноуровневой классификации. Бумага также опубликована на arxiv Сервер препринта.
Хотя некоторые утверждают, что глубокое обучение может надежно обеспечить мелкозернистую классификацию и вывести более широкие категории, эта тактика работает только с четкими изображениями.
«Реальные приложения включают в себя множество несовершенных изображений. Если модель фокусируется только на мелкозернистой классификации, она сдается до того, как начнется на изображениях, которые не имеют достаточного количества информации, чтобы поддержать этот уровень детализации»,-сказала Стелла Ю, профессор компьютерных наук и техники в UM, и автора исследования.
Иерархическая классификация преодолевает эту проблему, предоставляя классификацию на нескольких уровнях детализации для одного и того же изображения. Тем не менее, до этого момента иерархические модели боролись с несоответствиями, которые связаны с рассматриванием каждого уровня как собственной задачи классификации.
Например, при идентификации птицы мелкозернистая классификация часто зависит от местных деталей, таких как форма клюва или цвет перьев, в то время как грубые этикетки требуют глобальных функций, таких как общая форма. Когда эти два уровня отключены, это может привести к тому, что тонкий классификатор, предсказывающий «зеленый попугай», в то время как крупный классификатор предсказывает «растение».
Вместо этого новая модель фокусирует все уровни на одном и том же объекте на разных уровнях детализации, выравнивая тонкие предсказания посредством сегментации внутриизвья.
Предыдущие иерархические модели, обучаемые от грубых к конкретному, сосредоточившись на логике семантической маркировки, которая течет от общего к специфическому (например, птица, колибри, зеленый отшельник). Вместо этого H-Cast тренируется в визуальном пространстве, где распознавание начинается с мелких деталей, таких как клювы и крылья, которые состоит из более грубых структур, что приводит к лучшему выравниванию и точности.
«Большая часть предыдущей работы в иерархической классификации была сосредоточена только на семантике, но мы обнаружили, что последовательное визуальное обоснование на разных уровнях может иметь огромное значение. Поощряя модели« увидеть »иерархию визуально последовательным образом, мы надеемся, что эта работа вдохновит на более интегрированные и интерпретируемые системы распознавания», — сказал Seulki Park, постокорный научный сотрудник, ведущий научно -научный сотрудник и инженерные науки и инженеры в университете.
В отличие от предыдущих методов, исследовательская группа использовала неконтролируемую сегментацию — типично используемой для идентификации структур в более широком изображении — для поддержки иерархической классификации. Они демонстрируют, что его механизм визуальной группировки может быть эффективно применен к классификации, не требуя меток на уровне пикселей и помогает улучшить качество сегментации.
Чтобы продемонстрировать эффективность новой модели, H-CAST был протестирован на четырех наборах данных и сравнивал с иерархическими (FGN, HRN. Transhp, Hier-Vit) и базовыми моделями (Vit, CAST, HIE).
«Наша модель превзошла клип с нулевым выстрелом и современные базовые показатели по иерархическим критериям классификации, достигая как более высокой точности, так и более последовательных прогнозов»,-сказал Ю.
Например, в наборе данных о породах точность полной дорожки H-Cast была на 6% выше, чем в предыдущем современном, и на 11% выше, чем базовые.
Анализ ближайшего соседей на уровне функций также показывает, что H-Cast RetieS семантически и визуально последовательные образцы по уровням иерархии-в отличие от предыдущих моделей, которые часто получают визуально схожие, но семантически неверные образцы.
Эта работа потенциально может быть применена к любой ситуации, которая требует понимания многоуровневых изображений. Это может особенно принести пользу мониторингу дикой природы, идентифицируя виды, где это возможно, но отступает на более грубые прогнозы. H-CAST также может помочь автономным транспортным средствам интерпретировать несовершенный визуальный вклад, такой как окклюзированные пешеходы или отдаленные транспортные средства, помогая системе принимать безопасные, приблизительные решения на более грубых уровнях детализации.
«Люди, естественно, возвращаются к более грубым концепциям. Если я не могу сказать, имеет ли изображение из Пемброк -Корги, я все равно могу с уверенностью сказать, что это собака. Но модели часто терпят неудачу при таком гибком рассуждении. Мы надеемся в конечном итоге создать систему, которая может адаптировать уровень прогнозирования, как и мы», — сказал Парк.
H-CAST обучали и протестировали с использованием высокопроизводительных вычислений ARC в UM.
UC Berkeley, MIT и масштабированные основы также способствовали этому исследованию.
Больше информации:
Seulki Park, et al. Визуально последовательная иерархическая классификация изображений. Международная конференция по обучению представлений (2025).
Seulki Park и др., Визуально последовательная иерархическая классификация изображений, arxiv (2024). Doi: 10.48550/arxiv.2406.11608
Информация журнала:
Arxiv предоставлен Университетом Мичиганского инженерного колледжа
Цитирование: Model AI классифицирует изображения с иерархическим деревом от широкого до конкретного (2025, 14 мая), полученного 15 мая 2025 года из этого документа, подлежит авторским праву. Помимо каких -либо справедливых сделок с целью частного исследования или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Контент предоставляется только для информационных целей.