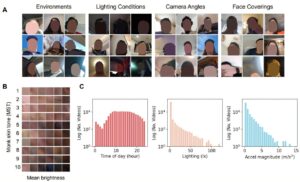
Данные, используемые для ДНК -экспериментов. Кредит: Интеллект природы (2025). Doi: 10.1038/s42256-025-01003-z
Исследователи из факультета компьютерных наук Генри и Мэрилин Тауб разработали метод, основанный на искусственном интеллекте, который ускоряет поиск данных на основе ДНК на три порядка, при этом значительно повышая точность. Исследовательская группа включала докторскую степень Студент Омер Сабари, д-р Даниэлла Бар-Лев, доктор Итай Орр, профессор Эйтан Яакоби и профессор Туви Эцион.
Исследование опубликовано в журнале Интеллект природыПолем
Хранение данных ДНК — это новое поле, которое использует ДНК в качестве платформы для хранения информации. ДНК предлагает значительные преимущества в качестве среды для хранения, в том числе:
- Долгосрочное сохранение: в 2013 году исследователи в Дании успешно извлекли ДНК из конной кости, начиная с 700 000 лет. В 2021 году международная команда восстановила ДНК из мамонтов, которые жили более миллиона лет назад. Напротив, магнитные диски, используемые в центрах обработки данных, имеют срок службы, измеренные за годы или, в лучшем случае, несколько десятилетий. Это подчеркивает потенциал ДНК для долгосрочного хранения.
- Энергетическая и экономическая эффективность: «облако», которое питает большую часть современных вычислительных услуг, опирается на центры обработки данных, которые потребляют приблизительно 3% глобального электроэнергии и выделяют около 2% от общего количества выбросов углерода. При экспоненциальном росте данных ожидается, что воздействие существующих технологий на окружающую среду значительно увеличится.
- Непревзойденная плотность данных: хранилище ДНК предлагает плотность данных в 100 миллионов раз больше, чем традиционное цифровое хранилище. Это означает, что объем, в настоящее время содержащий один мегабайт, может теоретически хранить до 100 терабайт с использованием ДНК.
ДНК представляет собой молекулу, состоящую из последовательности органических соединений, называемых нуклеотидами. Эти нуклеотиды классифицируются на четыре типа, представленные буквами A, C, G и T. В отличие от традиционных вычислений, где данные кодируются только двумя цифрами (0 и 1), хранилище ДНК основано на последовательностях из четырех букв, что значительно увеличивает количество возможных комбинаций.
Чтобы написать (хранить) данные в этой технологии, требуется синтез ДНК — создание молекул ДНК на основе последовательностей, кодирующих информацию. Для чтения хранимых данных необходимо секвенирование ДНК.
Пробные трубки, содержащие ДНК, кодирующие информацию. Кредит: Rami Shlush Проблемы в хранении данных ДНК
Разработка технологии хранения на основе ДНК представляет несколько технологических проблем:
- Как синтез, так и секвенирование-это длительные и подверженные ошибкам процессы, вводя ошибки удаления, вставки и замещения
- Из -за ограничений процесса синтеза образуются несколько копий каждой молекулы ДНК, кодирующих данные. Эти копии хранятся вместе, неупорядоченные, в контейнере для хранения
- Во время секвенирования получаются многие ошибочные копии этих молекул — наиболее содержащие ошибки, в то время как некоторые исчезают исключительно
Dnaformer: поиск данных с AI
Текущее исследование представляет собой комплексное вычислительное решение для извлечения и исправления ошибок в сложных системах хранения на основе ДНК. Используя передовые алгоритмы и методы кодирования, исследователи продемонстрировали, что их решение уменьшает поиск данных и время чтения с нескольких дней до всего лишь 10 минут.
Разработанный технологий метод DnaFormer основан на модели трансформатора, обученной моделируемым данным (генерируемым с использованием симулятора, которая также была разработана при технике) для восстановления точных последовательностей ДНК из ошибочных копий. Метод также включает в себя пользовательский код коррекции ошибок, адаптированный для ДНК, обеспечивая надежную целостность данных.
Кроме того, дополнительный механизм поля безопасности обнаруживает особенно шумные последовательности ДНК (нежелательные сигналы или ошибки, которые возникают в процессе секвенирования, которые могут влиять на точную интерпретацию данных) и применяет мощные алгоритмические инструменты для их эффективного обработки. В конце процесса данные преобразуются обратно в цифровую информацию.
Новый метод обеспечивает чтение 100 мегабайт данных со скоростью в 3200 раз быстрее, чем наиболее точный существующий метод — без какой -либо потери точности. По сравнению с ранее известными быстрыми методами Dnaformer также повышает точность на 40%, при этом значительно сокращает время обработки. Это было продемонстрировано на наборе данных 3,1-мегабайта, который включал:
- Цвет еще изображение
- 24-секундный аудиоклип слов астронавта Нила Армстронга на Луне
- Письменный текст, обсуждающий преимущества ДНК как многообещающий метод хранения данных
- Случайные данные, чтобы проиллюстрировать применимость к зашифрованным или сжатым данным
Исследователи планируют разработать индивидуальные версии DNAformer, адаптированные к различным потребностям. Они подчеркивают, что их технология масштабируется и адаптируется, что означает, что она может быть оптимизирована для крупномасштабных приложений для хранения данных, удовлетворения потребностей рынка и будущего синтеза ДНК и секвенирования.
Больше информации:
Daniella bar-lev и др., Масштабируемое и надежное хранение на основе ДНК посредством теории кодирования и глубокого обучения, Интеллект природы (2025). Doi: 10.1038/s42256-025-01003-z
Информация журнала:
Интеллект природы, предоставленная технологическим институтом Техниона — Израильский институт
Цитирование: Хранение данных ДНК: метод AI ускоряет поиск данных в 3200 раз (2025, 21 марта). Получено 22 марта 2025 года из этого документа подлежит авторским праву. Помимо каких -либо справедливых сделок с целью частного исследования или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Контент предоставляется только для информационных целей.