Vespa.AI спонсировал этот пост.
Это вторая из двух частей. Прочитайте также:
- Векторный поиск достигает своего предела. Вот что будет дальше
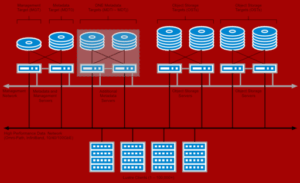
В части 1 мы исследовали растущие ограничения систем поиска только вектором, подчеркивая, как плоские встраиваемые встроены в сценариях, требующих структурированной фильтрации, обновлений в реальном времени, персонализированного ранжирования и мультимодального понимания.
По мере развития приложений ИИ ясно, что одного сходства семантического сходства недостаточно. Что нужно, так это структура — способ представлять отношения внутри и между модальностями в форме, которая является одновременно выразительной и эффективной.
Вот где входят тензоры.
В то время как векторы и тензоры технически являются одинаковым видом объекта-оба являются численными представлениями, используемыми в машинном обучении-вектор-это просто одномерный тензор. Тенсоры обобщают эту идею до нескольких измерений, что позволяет более богатым, более выразительным представлениям.
Поскольку тензоры сохраняют критический контекст-последовательность, положение, отношения и структура, специфичная для модальности,-это делает их намного лучше подходящими для передовых задач поиска, где имеют значение точности и объяснения.
Векторы против тензоров: быстрое сравнение
С первого взгляда векторы и тензоры могут выглядеть одинаково. Но когда дело доходит до выражения контекста и отношений, их возможности резко расходятся:
Тип данных
Векторное представление
Тензорное представление
Текст
[0.4, 0.2, 0.9]
текст[token][embedding]
Изображение
[0.1, 0.3, 0.7, …]
изображение[frame][region][channel]
Видео
[0.6, 0.8, 0.5, …]
видео[scene][timestamp][feature]
Векторы сглавят данные, представляющие все как единое встраивание. Тенсоры сохраняют структуру, позволяя:
- Мелкозернистый поиск, такой как сопоставление специфических токенов или областей изображения.
- Контекстные встраивания в рамках методов, которые сохраняют семантические и пространственные отношения.
- Точное взаимодействие запроса, где сходство является лишь одним из многих измерений.
Эти возможности делают тензоры основой для обеспечения современных методов поиска, таких как Colbert, Colpali и височный поиск видео, которые зависят от сравнения нескольких встроенных въездов по документу, а не только от одного.
Попытка воспроизвести эти возможности только с помощью векторов приводит к хрупким архитектурам: внешние трубопроводы для повторного реэранирования, отключенные услуги модели для фильтрации и лоскутное одеяло компонентов, которые дорого поддержат и трудно масштабироваться.
Упрощенная тензора
В большинстве библиотек машинного обучения тензоры рассматриваются как неструктурированные, неявно упорядоченные массивы со слабым набором и непоследовательной семантикой. Это может создать серьезные проблемы в реальных приложениях:
- Большие, непоследовательные API, которые замедляют развитие.
- Отдельная логика для обработки плотных и редких данных.
- Ограниченный потенциал оптимизации и трудный для чтения код, подверженное ошибкам.
Эти ограничения становятся особенно болезненными в рабочих нагрузках, включающих гибридные данные, мультимодальные входы и сложные ранжирование или трубопроводы по выводу. Более практичный подход к использованию тензоров с трубопроводами из поиска добыченного поколения (RAG) должен следовать более формализованной структуре, в том числе:
- Минимальный композиционный набор тензоров.
- Единая поддержка плотных и редких измерений.
- Сильная набор с названными измерениями.
Давайте углубимся в них дальше.
Минимальные, композиционные тензоры операции
Минимальный, композиционный набор тензорных операций сохраняет мощную, но управляемую структуру. Заменив раздутые API на небольшой, математически обоснованный набор основных операций, это облегчает чтение, изучение и отладку кода, снижая при этом риск ошибок. Разработчики могут составить эти строительные блоки для выражения сложной логики, быстро адаптироваться к новым рабочим нагрузкам и избежать переписывания структуры.
Этот подход Lean также дает системе более четкий график вычислений, разблокируя лучшие возможности оптимизации, такие как векторизация, параллелизация и повторное использование памяти.
Единое обращение с плотными и редкими измерениями
Данные часто бывают как в плотных, так и в редких формах. Плотные данные могут быть внедрением изображения продукта, где представлен каждый пиксель или визуальная функция, что приводит к полному населению. С другой стороны, редкие данные могут быть атрибутами продукта, такими как бренд, размер или материал.
Во многих структурах эти два типа данных обрабатываются отдельно, с изображениями в одном формате и атрибутах в другом, требующих различных API и логики для каждого. Это разделение добавляет ненужную сложность к разработке, обслуживанию и оптимизации.
Представляя как плотные, так и разреженные данные в одной и той же унифицированной тензорной структуре, встраиваемые изображения продукта и его структурированные атрибуты могут быть беспрепятственно объединены в одном представлении, запрашивают вместе и подаются непосредственно в одном и том же конвейере по ранжированию или выводу без преобразования формата.
Преимущества двойные: разработчики должны работать только с одним согласованным API, уменьшая сложность и потенциал для ошибок, в то время как сама система может оптимизировать производительность во всех функциях одновременно.
В сценарии поиска или рекомендаций электронной коммерции эта единая обработка позволяет более точную оценку актуальности, смешивая визуальное сходство с фильтрацией на основе атрибутов в режиме реального времени, предоставляя более быстрые, более точные результаты для клиентов.
Сильная набор с названными измерениями
Сильная набор набора с названными размерами дает тензорам слой семантической ясности, которой не хватает большинству систем на основе общих массивов. Названные измерения действуют как читаемые на человеке этикетки для каждой оси в ваших данных (например, Product_id, Color_channel, TimeStamp), поэтому вместо того, чтобы жонглировать позициями в индексе, вы можете работать напрямую с значимыми идентификаторами.
Это делает вычисления более безопасными, предотвращая несоответствия измерений, которые могут молча давать неверные результаты, а также облегчение кода для понимания с первого взгляда. Результатом является структура, в которой логика является как явной, так и обслуживаемой, снижая дорогостоящие ошибки и ускоряя итерацию, не жертвуя точностью.
Почему будущее приложений искусственного интеллекта принадлежит тензорам
Векторный поиск был мощным фактором, но по мере того, как приложения становятся более сложными, динамическими и мультимодальными, векторы больше недостаточно. Тензоры обеспечивают основу, которой не хватает векторных систем. Если векторы помогают извлечь, тензоры помогают причине.
В отличие от плоских векторов, тензоры сохраняют структуру, включают гибридную логику и поддерживают значимые вычисления между различными типами данных. Благодаря профессиональной структуре Vespa, готовой к производству, организации могут плавно интегрировать плотные и редкие данные, персонализировать опыт в масштабе и принимать решения в режиме реального времени, все в одной высокопроизводительной платформе.
Сделать тензоры более практичными
Основанный на этих основных принципах, VESPA разработал строго определенный, сильно напечатанный тензорный формализм, чтобы сделать тензоры более практичными в масштабе. В отличие от многих структур машинного обучения, которые фокусируются исключительно на разработке модели, тензорная структура VESPA также предназначена для высокопроизводительных обслуживаний в производственных средах в реальном времени. Узнайте больше в этом отчете.
Vespa.AI-это платформа для создания приложений, управляемых искусственным интеллектом для поиска, рекомендаций, персонализации и тряпки. Он обрабатывает большие объемы данных и высокие показатели запросов, предлагая эффективные данные, вывод и управление логикой. Доступно как управляемый сервис, так и с открытым исходным кодом. Узнайте больше последних из Vespa.AI Trending Stories YouTube.com/thenewstack Tech, быстро движется, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Бонни Чейз-страстный маркетолог продукта в Vespa.AI с умением для перевода сложных концепций ИИ в пользовательские решения. С учетом более десяти лет стратегии продукта и выхода на рынок она процветает на пересечении технологий и потребностей клиентов. Подробнее от Бонни Чейз