Когда цитата Клейтона Коулмана была сброшена в Kubecon NA, она резонировала. Всего пять лет назад спросите любого инженера по надежности сайта (SRE) об их работе, и вы услышите о поддержании быстрого, масштабируемого и устойчивого веб -приложений. Сегодня? Пейзаж смещается под нашими ногами. Рабочие нагрузки с выводом ИИ-процесс, в котором обученная модель использует свои знания для прогнозирования новых данных,-становится таким же критическим, как и веб-приложения.
«Вывод — Относится к процессу, с помощью которого обученная модель применяет свои изученные шаблоны к новым, невидимым данным для генерации прогнозов или решений. Во время вывода модель использует свои знания, чтобы реагировать на реальные входные данные ».
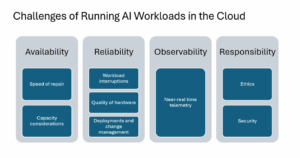
Эта эволюция требует новой дисциплины: инженерия надежности AI (Aire). Мы больше не просто сражаемся с шипами задержки в HTTP -запросах; Мы сталкиваемся с задержками генерации токенов в LLMS. Оптимизация запросов базы данных кажется почти странным по сравнению с оптимизацией модельных контрольных точек и тензоров. Модели ИИ, такие как веб -приложения перед ними, требуют сильной масштабируемости, надежности и наблюдаемости — но на уровне мы все еще архивируем.
Новая стека ИИ
Я провел почти два года глубоко в инженерии надежности искусственного интеллекта-исследования, прототипирование и создание реальных систем вывода. От конференций DevOps до SRE Days и сообщества встреч в Нюрнберге и Лондоне, я поделился с трудом заработанными уроками со сверстниками в этой области. Теперь я приношу эти идеи здесь.
Ненадежный ИИ хуже, чем нет ИИ.
- Вывод Не просто выполнение модели-это оперативная дисциплина с собственным набором архитектурных компромиссов и инженерных моделей. В отличие от обучения, где время и стоимость могут быть амортизированы, вывод находится на горячем пути. Каждая миллисекунд имеет значение.
- В режиме реального времени против партии: Вывод работает в двух разных режимах. В реальном времени (или в Интернете) есть такие впечатления от выводов, как чат-боты, обнаружение мошенничества и автомобили с самостоятельным вождением, где низкая задержка не подлежит обсуждению. С другой стороны, пакетный (автономный) вымывает большие наборы данных с запланированными интервалами для классификации изображений, журналов шахт или тенденций прогноза.
- Профили ресурсовХотя обычно и легче, чем обучение, вывод все еще требует точной инженерии. Приложения в реальном времени требуют не только быстрых вычислений, но и широко доступной инфраструктуры. CPU по-прежнему играют свою роль, но современные складки все чаще полагаются на графические процессоры, TPU или пользовательский кремний, такие как AWS Unferentia и Nvidia Tensorrt, для производительности с низкой задержкой.
- Развертывание следов: Вывод проходит в любом месте, от устройств с краями до гиперсценных облаков. Вы найдете его в конечных точках без серверов, кластерах Kubernetes и даже крошечных модулях IoT. Облачные платформы, такие как SageMaker, Vertex AI, обнимающее лицо и вместе.
- Оптимизация Playbook: Битва за скорость и эффективность продолжается. Команды используют квантование (FP32 → Int8), модель дистилляции и поиск нейронной архитектуры (NAS) для настройки производительности без ущерба для вывода. Цель? Меньшие, быстрее, более слабые двигатели вывода.
- Наблюдение и мониторинг: Традиционные телеметрические стеки терпят неудачу. Рабочие нагрузки для выводов требуют большего — отслеживания задержки прогнозирования, пропускной способности токена, дрейфа и даже показателей галлюцинации. Такие инструменты, как OpenElemetry, Prometheus и AI-коленные следы, больше не являются обязательными.
- Масштабируемость: Предсказуемый не является частью словарного запаса. Трафик вывода может вспыхивать с шаблонами использования, требуя агрессивного автомассалирования (Kubernetes HPA, облачный запуск) и интеллектуального балансировки нагрузки (Envoy, Istio или Kserve), чтобы оставаться впереди спроса.
- Фронт -линии безопасности: Ай вывод приводит к новым поверхностям атаки — от состязательных входов до рисков утечки данных. Инженеры должны защищать конечные точки модели, такие как API: с проверкой аутентификации, ограничения скорости, шифрования и целостности выполнения.
Вывод больше не просто подпроцесс машинного обучения. Это приложение. Это производствоПолем И это переопределяет эксплуатационный стек под ним.
Традиционные принципы SRE предлагают фундамент, но они не совсем подходят для ИИ.
- Вероятностная природа: Модели ИИ не детерминированные, как большинство веб -приложений. Один и тот же вход может дать разные выходы. Модель может похвастаться на 100% безоговорочно, но извергать неправильные, смещенные или бессмысленные результаты. Это принципиально меняет то, как мы определяем «надежный».
- Изменение метрик: Время UP -SLAS? Необходимо, но недостаточно. Добро пожаловать в мир точности SLA. Нам необходимо определить и измерить производительность на основе точности, отзывов, справедливости и дрейфа модели.
Новые испытания ИИ — День SRE — Aire 2025
- Эволюция инфраструктуры: Такие концепции, как вход и горизонтальный POD Autoscaling Evolve. Теперь нам нужны инструменты и методы, такие как Model Mesh, Lora Balancing, AI Gateways и динамическое распределение ресурсов, особенно для рабочих нагрузок с тяжелыми графиками. Сам Kubernetes адаптируется благодаря таким усилиям, как рабочие группы службы, DRA (динамическое распределение ресурсов) и API Gateway, чтобы лучше удовлетворить эти специализированные потребности.
- Пробелы в наблюдении: Стандартные инструменты хорошо отслеживают процессор, память и задержку, но часто пропускают такие проблемы с ИИ, как дрейф, оценки доверия или показатели галлюцинации. Нам нужна AI-специфическая наблюдаемость.
- Новые режимы отказа: Забудьте простые сбои. Теперь мы сталкиваемся с «молчаливой моделью деградацией» или «модельным распадом». Это постепенное, часто невидимое снижение производительности, точности или справедливости. Отношение к этому как к критическому инциденту по производству, требуется новое мышление и инструмент
Модельный распад — Молчаливая модель деградации — В отличие от традиционных проблем с программным обеспечением, которые вызывают немедленные сбои или ошибки, модели искусственного интеллекта могут опуститься молча, продолжая функционировать, но с все более неточными, смещенными или непоследовательными выходами.
Почему мы относимся к бесшумной модели деградации как к производственному инциденту
Потому что это один. В отличие от сбоя стручков или неудачных конечных точек, молчаливая модель деградации проскальзывает под радаром — модель продолжает реагировать, но ее ответы становятся слабыми, предвзятыми или просто неправильными. Пользователи не видят 500 ошибок; Они получают галлюцинации, токсичные результаты или неисправные решения. Это не просто ошибка — это нарушение доверия. В мире ИИ правильность — время безоговорочно. Когда надежность означает качество, деградация — это время простоя.
Расширение вывода API Gateway API, OpenInference и AI -шлюзы
Возможно, мы не будем просто расширить Kubernetes для ИИ — нам, возможно, потребуется его раскошелить.
Модели крупных языков (LLMS) требуют специализированной маршрутизации трафика, ограничения ставок и обеспечения безопасности, которые стандартные механизмы входа Kubernetes не были созданы для обработки. Kubernetes, архизированные вокруг бессмысленных веб -приложений, не были разработаны с учетом вывода. Пока он адаптируется, пробелы в ключе остаются.
Рабочие нагрузки вывода требуют жестко интегрированных решений для аппаратного ускорения, ресурсной оркестровки и высокопроизводительного управления трафиком. Экосистема Kubernetes догоняет такие инициативы, такие как WG-сервирование (нацеливание оптимизированной AI/ML-сервировки), управление устройствами (сфокусированное на интеграции графических процессоров/TPU через DRA) и развивающееся расширение вывода API шлюза, которое закладывает основы для масштабируемого и безопасного маршрутизации конечной точки LLM. Между тем, появляются новые шлюзы AI, чтобы заполнить пустоту, обеспечивая логику маршрутизации, наблюдение и контроль доступа, адаптированные к выводу.
Тем не менее, мы наслоим ИИ поверх системы оркестровки, которая изначально не предназначена для этого. Объявление Google о поддержке кластеров Kubernetes 65K-узла путем обмена и т. Д. С помощью подсказок хранения, поддерживаемых галезом в будущем, где могут потребоваться основополагающие изменения. Возможно, мы не будем просто расширить Kubernetes для ИИ — нам, возможно, потребуется его раскошелить.
Итак, как мы применяем практики SRE к этой новой реальности ИИ?
- Определите AI-ориентированные SLIS / SLA: Выходите за рамки UPTICE, чтобы включить точность, справедливость, задержку и цели дрейфа. Установите четкие обязательства (SLA) для таких показателей, как TTFT (время до первого токена) и TPOT (время на токен на выход), точность или границы смещения.
- Постройте наблюдение ИИ: Реализуйте надежный мониторинг с использованием таких инструментов, как OpenElemetry и Grafana, но дополняют их с помощью AI-специфических платформ и оценки (OpenInerence), чтобы отслеживать метрики, такие как распределение откликов моделей, показатели доверия и типы ошибок (например, галлюцинации).
- Разработать ответ на инцидент ИИ: Создайте воспроизведения специально для сбоев искусственного интеллекта, таких как внезапный дрейф или шипы смещения. Реализуйте автоматические откаты в стабильные версии модели или автоматические выключатели AI.
- Инженер по масштабе и безопасности: Методы левереджа, такие как балансировка нагрузки по моделям, кэширование, оптимизированное планирование графических процессоров (область, все еще развивающаяся в Kubernetes), и AI-шлюзы для управления трафиком, безопасность (например, ограничение ставок на основе токнов, семантическое кеширование) и разрешение. Защитите целостность модели посредством отслеживания происхождения, безопасного распределения и мониторинга времени выполнения.
- Непрерывная оценка: Оценка модели не является разовой задачей. Он охватывает предварительное развернение (автономные тесты), предварительное высвобождение (тесты Shadow/AB) и непрерывный мониторинг после развертывания для дрейфа и деградации.
Пример оценки модели SLA в производстве
AI Gateways: инструмент SRE для эпохи ИИ
В первые дни SRE мы полагались на балансировщики нагрузки, сетки обслуживания и шлюзы API для управления трафиком, обеспечения политики и поддержания наблюдаемости. Сегодня рабочие нагрузки вывода требуют одинаковых — но с большей сложностью, большей масштабами и гораздо меньшей терпимостью к задержке или неудачам. Вот куда входят шлюзы ИИ.
Думайте о них как о All-In-One Box для AI: Запросы на маршрутизацию на правильную модель, сбалансируя нагрузку на реплики, ограничение скорости соблюдения и безопасности
Политики и разоблачение глубоких крючков наблюдения — все это сразу. Такие проекты, как Gloo AI Gateway, продвигают это вперед. Они решают проблемы корпоративного уровня, такие как контроль затрат на модель, безопасность на основе токков и отслеживание ответов LLM в реальном времени-проблемы, для которых традиционные сетки обслуживания не были созданы.
Именно здесь SRE принадлежит сегодня: не только настройка автомасляров, но и управление плоскостью управления для интеллектуальных систем.
AI Gateway — это новый инструмент на нашем поясе — и, возможно, самый важный.
Третья эпоха SRE — инженерия надежности ИИ
Наша роль SRES развивается. Нам нужно любопытство, описанное в «97 вещах, которые каждый SRE должен знать» больше, чем когда -либо — стремление понять всю систему, от кремния до нюансов модельного поведения. Мы должны построить ИИ, которому мы можем доверять, используя новую экосистему инструментов и стандартов.
Бьорн Рабенштейн рассказал о «третьей возрасте» SRE, где его принципы становятся универсально встроенными. Хотя это правда, новая эра формирует ИИ. Инженерная инженерия AI — это не просто расширение SRE; Это фундаментальное изменение, смещающее внимание от надежности инфраструктуры к надежности самих интеллектуальных систем.
Потому что, если вывод действительно является новым веб -приложением, то обеспечение его надежности является новой эпохой SRE. А ненадежный ИИ? Это хуже, чем нет ИИ.
Trending Stories youtube.com/thenewstack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Технологический профессионал с более чем 17 -летним опытом работы в области телекоммуникации, разработки программного обеспечения, DevOps, SRE и Kubernetes. Взвешенные технические команды, соучредители стартапы и внесли свой вклад в облачные проекты. Тренер и спикер сосредоточились на практическом наставничестве в DevOps/SRE, Cloud Technologies и AI. Подробнее от Дениса Василова