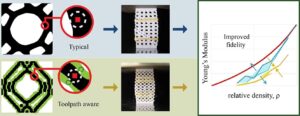
Instaclustr спонсировал этот пост.
Потоковые данные подкрепляют кампании персонализации в реальном времени, обнаружение мошенничества, прогнозирующее обслуживание и постоянно расширяющийся набор критически важных для бизнеса инициатив. С учетом того, что ИИ умножает значение этих вариантов использования, целостность этих данных является более важной, чем когда -либо.
Но ИИ-обоюдоострый меч. Те же системы, которые обеспечивают новую бизнес -ценность, также вводят новые поверхности атаки. Согласно недавнему отчету NetApp по сложности данных, 69% предприятий сообщили о повышенных угрозах безопасности из -за ИИ. Большинство лидеров C-Suite назвали глобальный риск безопасности в качестве главного источника стресса, и это давление будет усилить только так, как потоковые данные становятся более глубоко встроенными в основные системы.
Защита потоковых данных больше не является лучшей практикой ИТ. Это стратегический императив. Эти пять стратегий, испытываемых на предприятиях, обеспечивают план для строительства безопасных, масштабируемых потоков данных, готовых к эпохе ИИ.
1. Используйте открытый исходный код на уровне данных
Технологии с открытым исходным кодом, такие как Apache Kafka, доминируют в ландшафте потоковых данных не только для масштабируемости, но и для безопасности. Сообщество активного развития Кафки непрерывно исправляет уязвимости, стресс-тестирование и укрепляет защиту быстрее, чем альтернативы с закрытым исходным кодом.
Далеко не от ответственности, открытый код (и под этим я имею в виду 100% открытый исходный код, а не альтернативы открытого ядра, которые способствуют блокировке), является большой силой. Прозрачность обеспечивает быстрое обнаружение и реагирование риска, а предприятия получают больше, чем просто безопасность. Они также получают модульные, интегрирующие AI-архитектуры с долгосрочной жизнеспособностью.
2. Заблокировать доступ к данным
Потоковые данные никогда не должны быть широко открыты на предприятии. Управление доступа наименьшего количества привилегирования, применяемые через модели управления на основе ролей (RBAC) или на основе атрибутов (ABAC), ограничивают каждого пользователя или приложение только тем, что важно.
Мелкозернистые списки управления доступом (ACL) Добавьте еще один уровень защиты, ограничивая доступ к чтению/записи только на необходимые темы или каналы. Объедините эти элементы управления с многофакторной аутентификацией, и даже скомпрометированные учетные данные вряд ли дадут злоумышленникам значимый охват.
3. Плач
В 2024 году мы увидели более 40 000 общих уязвимостей и воздействия (CVE), исторического максимума. Этот год уже находится в темпах, чтобы побить этот рекорд, и прогнозируется более 50 000 уязвимостей.
Тем не менее, слишком много предприятий отстают в обычных обновлениях, оставляя эксплуатационные дыры в своей инфраструктуре. Потоковые платформы данных (часто высокопроизводительная и всегда включенная) не могут позволить себе этот риск. Предприятия должны рассматривать исправление как критическую безопасность операции, а не с бэкэнд-задачей.
Автоматизировать, где это возможно. Следите за подачи CVE. Установите соглашения на уровне обслуживания (SLA) для применения обновлений высокого приоритета. Бдительность принесет дивиденды.
4. Переезд в частные сети
Пиринговые и частные сетевые настройки виртуального частного облака (VPC) необходимы для предприятий, которые хотят обеспечить безопасность потоковой передачи данных при транспортировке. Эти конфигурации гарантируют, что данные никогда не касаются общедоступного Интернета, что устраняет воздействие распределенного отказа в обслуживании (DDO), атаки человека в среднем и внешней разведке.
Помимо безопасности, частная сеть повышает производительность. Это уменьшает джиттер и задержку, что имеет решающее значение для приложений, которые полагаются на предоставление подключения или отзывчивости модели искусственного интеллекта. В то время как VPC Peering принимает вдумчивую настройку, выгоды в надежности и защите стоят инвестиций.
5. рассматривать правила конфиденциальности данных как требования архитектуры
Правила конфиденциальности данных, такие как GDPR, HIPAA и PCI-DSS, должны рассматриваться как основные архитектурные принципы, а не только флажки соответствия. Предприятия, которые определяют приоритеты конфиденциальности с самого начала, лучше расположены для создания устойчивых систем, которые противоречат анализу и масштабированию без риска.
Это означает разработку потоковой архитектуры для поддержки анонимизации данных в точке приема, устанавливая четкие политики хранения, которые избегают ненужного хранения данных и реализуют мониторинг в реальном времени для обнаружения необычных моделей доступа или поведения. Когда произойдут компромиссы, команды должны быть в состоянии быстро реагировать, подкрепленные подробными журналами и оповещениями, которые отображаются непосредственно на требования к регулирующей отчетности.
Не менее важно, что безопасность должна быть включена в культуру. Предприятия, которые регулярно обучают своих сотрудников к конфиденциальности и защите данных (не только технических команд, но и любой, кто касается данных о клиентах), склонны выявлять проблемы раньше и быстрее восстанавливаться. Конфиденциальность за дефицитом не просто юридическая стратегия. Это оперативное преимущество.
Безопасность сейчас, масштабируйте с уверенностью
Потоковые данные являются нервной системой современных предприятий, и их стоимость только будет расти. Но без строгих методов безопасности это также является ответственностью. Внедряя эти пять стратегий, лидеры предприятия могут создавать масштабируемые, безопасные трубопроводы данных, которые поддерживают инновации, не жертвуя безопасностью. Цель не только чтобы оставаться впереди злоумышленников, но построить достаточно сильную основу, чтобы поддержать любое будущее, наступающее AI, будет дальше.
Instaclustr обеспечивает надежность в масштабе с помощью интегрированной платформы данных с открытым исходным кодом, таких как Apache Cassandra®, Apache Kafka®, Apache Sparktm, Elasticsearchtm, Redistm, Apache Zookeepertm и Postgresql®. Узнайте больше последних из Instaclustr Trending Stories YouTube.com/ThenewStack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Анил Инамдар является глобальным руководителем отдела данных в NetApp Instaclustr, которая предоставляет управляемую платформу вокруг технологий данных с открытым исходным кодом, включая Cassandra, Kafka, Postgres, Clickhouse и Opensearch. Анил имеет более 20 лет опыта работы в ролях данных и аналитики …. Подробнее от Anil Inamdar