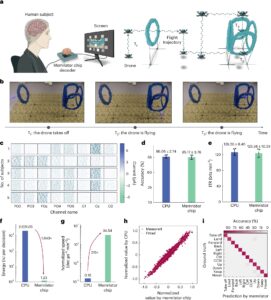
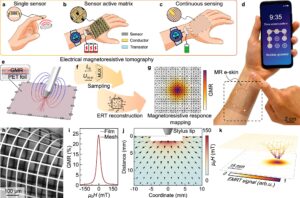
В среду была признана ранняя теоретическая работа исследователей по обучению подкреплению, так как Ассоциация по компьютерному оборудованию названа исследователями Эндрю Дж. Барто и Ричардом С. Саттоном в качестве победителей премии ACM Am Turing Ad Am Turn.
ACM
Оба исследователя имели решающее значение в разработке концептуальных и алгоритмических оснований обучения подкреплению, основы современных технологий агентов на основе искусственного интеллекта.
Они в совокупности составляют приз в размере 1 миллиона долларов (любезно предоставлены Google) за свои труды.
Премия ACM Am Turing часто известна как «Нобелевская премия в области вычислений» и названа в честь Алана М. Тьюринга, британского математика, который сформулировал математические основы вычислительной техники, а также придумал тест Тьюринга, мысленный эксперимент (и текущий эталон) для оценки того, достигла ли машина, подобное человеческому интеллектуальному поведению.
Таким образом, награда этого года довольно подходит для его тезки.
«В лекции 1947 года Алан Тьюринг заявил:« То, чего мы хотим, — это машина, которая может извлечь уроки из опыта », — отметил Джефф Дин, главный ученый Google DeepMind, в своем заявлении. «Обучение подкреплению, как пионера Барто и Саттоном, непосредственно отвечает на вызов Тьюринга. За последние несколько десятилетий их работа стала линчпином прогресса в ИИ ».
Барто является почетным профессором информации и компьютерных наук в Университете Массачусетса, Амхерст. Саттон является профессором компьютерных наук в Университете Альберты, а также научным сотрудником в Keen Technologies («усилие AGI Джона Кармака»), а также сотрудник Института интеллектуальной разведки Альберты.
Полное агентство
Обложка для подкрепления учебной книги
Подкрепление обучения, вдохновленное идеями в нейробиологии и даже психологии, сформировало основу агентского ИИ или основы компьютерных объектов, которые воспринимают и действуют, предпочтительно действуя таким образом, чтобы выполнить намерение пользователей. Для этого агенты полагаются на «награды» или отзывы о качестве их поведения,
Барто и Саттон разработали многие основы обучения подкреплению и поделились своим обучением в учебнике «Обучение подкреплению» 1998 года «Обучение подкреплению: введение».
Работа, основанная на процессах принятия решений Маркова (MDP), в которой агент принимает решения в случайной среде и получает сигнал вознаграждения после каждого действия с целью максимизации своих вознаграждений.
MDP предположил, что агент знал о своих окрестностях. Подкрепление обучения сделало следующий шаг, и предполагали, что агенты ничего не знали об окружающей среде или ее наградах.
«Минимальные информационные требования к обучению подкрепления в сочетании с общностью средств MDP позволяют применять алгоритмы обучения подкреплению к обширному диапазону проблем», — говорится в объявлении ACM.
Дуэт был первым, кто обнаружил, что нейронные сети могут представлять ученые функции и что агенты могут сочетать обучение и планирование. Приобретение знаний об окружающей среде может быть основой для планирования.
Некоторые из других методов, которые пионеровали дуэтом-работая друг с другом или другими исследователями-включают обучение временным различиям, которое помогло решить проблемы прогнозирования вознаграждения, а также методы политики для устранения этих высокоразмерных действий, где обучение подкрепления терпит неудачу.
Успешные приложения
Подкрепление Learning получила свою первую большую победу, победив лучших игроков Human Go в 2016 и 2017 годах через компьютерную программу Alphago.
Системы ИИ, спустившиеся от Альфаго, были адаптированы для решения других проблем. В 2022 году исследователи использовали одну такую систему для обнаружения новых алгоритмов для фундаментальной математической задачи, называемой умножением матрицы. 4/6 pic.twitter.com/pjpebczc1m
— Quanta Magazine (@quantamagazine) 5 марта 2025 г.
CHATGPT Openai также обязан своим успехом подкреплению обучения. Согласно ACM, для обучения своих крупных языковых моделей, сервис использует технику, называемую подкреплением, обучающимся на обратной связи с человеком (RLHF) для охвата ожиданий человека.
Trending Stories youtube.com/thenewstack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Joab Jackson является старшим редактором нового стека, охватывающего облачные нативные вычисления и системы системы. Он сообщил об инфраструктуре и развитии IT более 25 лет, в том числе в IDG и государственных компьютерных новостях. До этого он … читал больше от Джоаба Джексона