В течение десяти лет Slack выполняла задания Cron на одном сервере. Но когда на сервере начались проблемы и пережевывать время обслуживания, администраторы компании знали, что понадобился более устойчивый планировщик работы. Итак, они превратили Крона в распределенную систему.
В разговоре на саммите Scylladb Scale Monster, который проводился практически на прошлой неделе, Клэр Адамс, инженер -программист по инфраструктуре Slack, рассказала, как поставщик услуг сотрудничества превратил Cron Unix Pradening Cron в распределенную услугу,
«Людям действительно было надоело иметь дело с этим короком Cron. Никто на самом деле не хотел сохранить это. Это было установлено давным -давно », — сказал Адамс. «У людей были некоторые унаследованные знания, но ни у кого на самом деле не было полных знаний по всем причудливым вещам».
«Нам нужно было что -то более надежное».
Крон для одного
Как и каждый Hardcore Linux, знает, что Cron-это планировщик заданий, основанный на времени, позволяющий администраторам запускать сценарии и приложения в определенное время и даты, планируя их в файле, называемом Crontab.
Как вы можете себе представить, Slack, с более чем 38 миллионами ежедневных пользователей, имеет много задач для выполнения.
В целом, Slack имеет около 385 крон сценариев, которые в совокупности выполняют 2000 в час, что составляет до 340 000 рабочих мест в неделю или 20 миллионов в год.
Для Slack Cron обрабатывает задачи по питанию обе пользовательские функции, такие как напоминания и уведомления по электронной почте, а также обязанности по обслуживанию, такие как очистка базы данных и работающие аналитические задания.
В течение первых 10 лет Slack Cron запустили из одного Crontab, работая на одном сервере на веб -сервисах Amazon.
Однако у системы были свои ограничения. Особенно сложными были обновления программного обеспечения, которые были сделаны путем дублирования службы на другом сервере, а затем переключение — достаточно быстро, чтобы не пропустить никаких запланированных заданий.
Последняя капля, однако, заключалась в том, что в прошлом году сервер Cron продолжал спотыкать от ошибочных ошибок вне памяти, что требует ручного восстановления. Больше времени простоя.
«У нас не может быть много инцидентов, которые могут повлиять на пользователей. Мы должны быть более надежными и стабильными в качестве продукта », — сказал Адамс. «Так что это привело нас к этому переписать».
Распределенная замена
Ясно, что понадобится система планирования, распределенную по нескольким серверам. Переходя к распределенной системе, компания надеялась повысить надежность, сократить окна технического обслуживания и получить больше понимания заданий, которые были выполнены.
Были разные подходы, которые команда могла выбрать. Например, Slack-большой пользователь Kubernetes, поэтому они исследовали, используя собственный встроенный Cron Kubernetes Cronjob. Такой подход, однако, потребовал бы вращения 53 000 стручков в день, и было бы трудно отлаживать. И придется требовать, чтобы пользователи переписывали свои сценарии. Итак, крупные хлопоты.
Тем не менее, «для нас имело смысл использовать технологии, в которые мы уже инвестировали», — сказала она.
Это помогает получить службу выполнения работы монстра
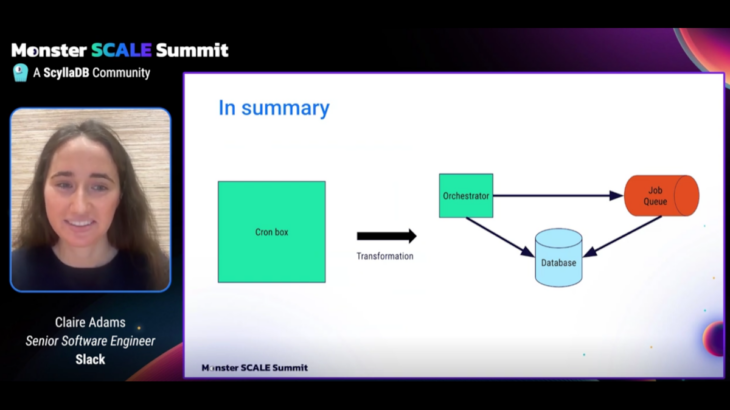
В конце концов, потребовалось три разных компонента, чтобы заменить ящик Cron One-Mighty.
Система будет продолжать использовать Cron, который будет запускать сценарии Cron без модификации. Но вместо того, чтобы запустить задания в своей памяти, Крон передал их отдельному механизму выполнения заданий.
Как это произошло, компания уже построила и поддерживала асинхронную вычислительную платформу или службу выполнения заданий. Основываясь на Kubernetes и написано на языке программирования GO, это был зверь, выполняя 10 миллиардов рабочих мест в день.
Но, достаточно удивительно, у него не было планировщика. Просто очереди. Сам Крон — очень хороший планировщик. И, к счастью, у Go есть библиотека Cron, которая может быть использована. Это означало, что ни один из сценариев Cron не должен был быть переписан.
В этой настройке все рабочие места Cron получают свою собственную выделенную очередь. Каждый сценарий завершен как задание, чтобы его можно было выполнить.
Очередь выполняется через Кафку, причем каждая работа получает свою собственную тему Кафки. Экземпляр AWS EC2 фактически выполняет работу.
Поскольку сервер Cron не выполнял сценарии в своей собственной памяти, он все еще мог работать на одном сервере.
Первоначально команда дизайнеров рассмотрела подход к распространению сценариев на нескольких серверах Cron, но это приведет к большому количеству сложности, определяя, какой сервер должен запускать этот сценарий.
Вместо этого команда пошла с другим подходом: выборы лидеров с блокировкой.
Вместо того, чтобы каждый сервер выполнял некоторые сценарии, сервер лидера выполнил все сценарии, передав их в механизм заданий. Серверы резервного копирования были готовы вступить во владение, если основной сервер быстро не удастся.
Последней частью системы была база данных, которая будет отслеживать, как выполнялись сценарии. Как правило, эта информация встречается в журналах Cron, записанных на сервере, хотя их трудно отслеживать и разрабатывать.
Разве не было бы лучше иметь централизованный портал, где сохранялись все статусы, предоставляя такую информацию, когда в последний раз, когда работал, если он был успешным? Это роль базы данных.
Больше компонентов, но легче управлять
Добавление еще нескольких сценариев Cron к исполнителю работы монстра на 10 миллиардов человек в день оказался без проблем. В качестве бонуса это была зрелая, полностью поддерживаемая система.
«Мы уже инвестировали годы в создание этой системы очереди работы очень надежной, очень масштабируемой, имели хорошие гарантии и имели хорошее вращение по вызову и хорошее техническое обслуживание»,-сказал Адамс, вспоминая рассуждения на данный момент. «Так что, если мы сможем просто использовать это, [IT would] Сделайте нашу жизнь на тонну легче ».
Прошло около года с тех пор, как Slack мигрировала на распределенный Cron. До сих пор новая система успешно выполнила более шести миллионов сценариев. Более того, он уменьшил бремя по вызову, освобождая администраторов от сброса сервера каждый раз, когда его переживают ошибкой памяти.
«Несмотря на то, что есть больше компонентов, его легче поддерживать», — сказал Адамс.
Адамсский вывод? Используйте то, что у вас есть. В их случае это была существующая очередь работы, Голанг и Кубернет. «Вы уменьшаете бремя обслуживания, получая огромные победы»,-сказала она.
И даже скромная коробка Cron провели урок или два.
«Slack выполнял ключевую функциональность в течение 10 лет на одном узле. Это много времени, чтобы справиться с этой менее идеальной системой. Но это было достаточно хорошо. Это сделало работу. И я думаю, что это действительно ключевой вынос », — сказала она. «Это нормально, чтобы сделать это действительно простым, даже если это как -то ловко, в течение долгого времени».
«А потом, когда вам сыт по горло, вы можете попробовать что -то лучше».
Посмотреть всю презентацию здесь:
Trending Stories youtube.com/thenewstack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Joab Jackson является старшим редактором нового стека, охватывающего облачные нативные вычисления и системы системы. Он сообщил об инфраструктуре и развитии IT более 25 лет, в том числе в IDG и государственных компьютерных новостях. До этого он … читал больше от Джоаба Джексона





















