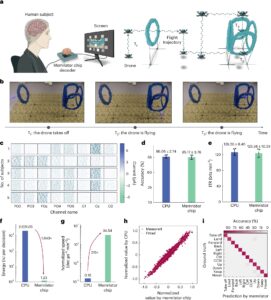
Signadot спонсировал этот пост.
В течение многих лет обещание CI/CD было святым Граалем доставки программного обеспечения. Мы инвестировали бесчисленные часы и миллионы долларов в оптимизацию трубопроводов, автоматизировать сборки и преследовать этот неуловимый «зеленый» статус. Нам сказали, что быстрый и эффективный трубопровод является ключом к программному обеспечению доставки быстрее.
И какое -то время это сработало.
Но для облачных нативных команд, создающих децентрализованное программное обеспечение на основе микросервисов, возникла новая и коварная проблема. Узкое место больше не в процессе трубопровода — оно находится в самой инфраструктуре. В частности, общая постановка стала новым узким местом, которое поражает скорость выпуска, расстраивает инженеров и создает «игру вины», которую никто не выигрывает.
Это не просто незначительное неудобство; Это фундаментальная проблема масштабирования. Старая модель единой общей, долгоживущей ставной среды создает игру с нулевой суммой. Команды находятся в постоянной борьбе за то, чтобы внести свои изменения в общую среду, которая постоянно ломается, что приводит к тому, что часы, потраченные на попытку выяснить, кто вызвал проблему. Этот сценарий приводит к задержкам в выпусках или доставке с меньшей уверенностью, потому что чистое окно тестирования никогда не было доступно. Директор по технике инженерии для команды из 100 человек назвал это «гонкой слияния, за которой следует игра вины».
Разработчики проводят большую часть своих циклов тестирования во внешней петле, которая является медленной и утомительной. Внутреннее тестирование петли ограничено базовым блоком и издеваточным тестированием, которое пропускает обратную связь по интеграции.
Скрытые затраты на сломанную стадию
Влияние этого узкого места является массивным и далеко идущим, что выходит далеко за рамки только что задержки.
1. Потеряв производительность и разочарование разработчика
Эта проблема попадает в центр продуктивности разработчика. Когда разработчик заканчивает свою функцию, их работа не выполнена; Он только что вступил в очередь. Они не могут проверить свой код в реалистичной среде, поэтому их импульс. Среднее время, чтобы получить запрос на вытягивание (PR) в общую стадирующую среду и получить обратную связь, может простираться от нескольких часов до дней.
Как я писал ранее, влияние сломанной постановки обстановки далеко идущие. Когда постановка нестабильна, ваш тщательно спланированный график выпуска выходит из окна. Ничто не убивает производительность быстрее, чем ожидание, когда станет доступной или стабильной среды.
Для команды инженеров из 100 человек, даже консервативная оценка восьми потерянных продуктивных часов на одного разработчика в неделю представляет собой потерю производительности в 20%, что ежегодно переводится на миллионы долларов в течение потерянных инженерных мощностей. AWS задокументировала, как его разработчик испытывает улучшения, обеспечил снижение затрат на 15,9% по сравнению с прошлым годом и 433% ROI в течение трех лет. Постоянное трение и отсутствие контроля над процессом тестирования разрушают доверие к системе и приводят к разочарованию.
2. Скомпрометированный качество и повышенный риск
Удлижеватая стационарная среда создает ложное чувство безопасности. Команды могут подумать, что медленный, ручный процесс обеспечивает качество, но наоборот верно. Когда трудно попасть в постановку, команды начинают избегать ее или тестировать менее тщательно. Это приводит к более крупному и более рискованному развертыванию, потому что несколько функций объединяются вместе, что делает практически невозможным определить источник ошибки.
Как отметил один комментатор, предполагается, что единственная постановка должна ловить ситуации, когда различные приложения не могут мирно сосуществовать в производстве. Но когда это нестабильно, вы в любом случае не можете доверять результатам теста, и вы получите неприятные сюрпризы в производстве. Это особенно верно для микросервисов, которые предназначены для независимого развертывания.
3. Оперативный хаос и эскалация затрат
Эта проблема не ограничивается только инженерной командой; Это создает значительное оперативное бремя. Команды по инфраструктуре и DevOps постоянно вводят в устранение неполадок и отлаживания «Кто сломал постановку», отводя время от стратегической работы. Окружающая среда становится снежинками, где ручные настройки и дрейф на конфигурацию заставляют ее медленно расходиться с производства, что еще больше снижает свою стоимость.
«Состояние отчета о доставке программного обеспечения» Circleci обнаружило, что высокоэффективные команды восстанавливаются после сбоев CI/CD за 15 минут или меньше, в то время как лучшие 5% восстанавливаются менее чем за пять минут. Тем не менее, большинство организаций борются с гораздо более длительным временем восстановления из -за сложности управления окружающей средой.
В то время как некоторые могут предложить создание большего количества среды для постановки, это только умножает проблему. Каждая новая среда требует технического обслуживания, мониторинга и синхронизации данных, что приводит к стремительно растущей стоимости и еще более сложному логистическому кошмару.
Ответ инженерного платформы
Индустрия отреагировала на эти проблемы с помощью инициатив инженерии платформы. Gartner прогнозирует, что к 2027 году 80% крупных организаций по разработке программного обеспечения создадут инженерные команды платформы, по сравнению с 45% в 2022 году. По прогнозам, на 2033 году рынок инженерии платформы стоимостью 5,1 миллиарда долларов сша достигнет 51 миллиард долларов.
Однако реализация остается сложной. «Состояние инженерного отчета о платформе 2024» показывает, что 45% команд платформы вообще ничего не измеряют, в то время как только 22% сообщили о значительных улучшениях после введения инженерии платформы.
«Здесь отражено, что для людей, которые хорошо проводят платформу -инженерию, и это работает для них, это впечатляет», — отмечает Сэм Барлиен, руководитель отдела сообщества Инженерной организации платформы. «И люди [who are not doing IT well]это полная противоположность впечатляющему. Люди понятия не имеют, что они делают ».
Новая модель: изолированное здравомыслие на общей инфраструктуре
Преобразование стационарной среды из среды монолитного тестирования в среду, которая поддерживает тестирование интеграции внутренней петли для разработчиков.
Так что, если CI/CD не проблема, а дублирующиеся среды не являются решением, что такое ответ?
Новая модель состоит в том, чтобы преобразовать существующую инфраструктуру для поддержки изолированного параллельного тестирования. Вместо того, чтобы бороться за одну монолитную среду, вы даете каждому разработчику личную, эфемерную «песочницу» для их функции.
Это не о копировании всего стека. Это старая, дорогая модель. Современный подход-это форма тестирования разработчиков в Канарском стиле. Вы сохраняете одну общую базовую среду, работающую — существующий кластер, а затем, для каждой новой функции, вы только «разбираетесь» с конкретными изменениями, которые меняются.
До: Единая, хрупкая стадическая среда, в которой сталкиваются изменения нескольких команд.
После: Общая стационарная среда с интеллектуальной маршрутизацией запросов, которая обеспечивает параллельное тестирование без дублирования среды.
Это достигается за счет интеллектуальной маршрутизации запросов, часто используя сервисную сетку. Когда разработчик хочет проверить свои изменения, устанавливается уникальный ключ маршрутизации, и интеллектуальная маршрутизация гарантирует, что трафик для их «песочницы» отправляется в раздробленные услуги, в то время как весь другой трафик продолжает достигать стабильного базового уровня. Это позволяет Dev A проверять их PR без влияния работы Dev B, даже если они имеют одинаковую базовую инфраструктуру.
Ведущие организации уже демонстрируют этот подход. Doordash реализовал системы для быстрого обратной связи в производственных средах, в то время как Lyft разработал сложные плоскости управления для управления общими средами разработки. Эти подходы значительно упрощают сложность архитектуры микросервисов без накладных расходов на полную среду дублирования.
Преобразующее влияние интеллектуальной инфраструктуры
Принятие этой модели приводит к глубоким улучшениям во всех аспектах доставки программного обеспечения:
Производительность разработчика: «Катастрофа очереди» устраняется. Разработчики больше не ждут промежуточного слота; Они могут проверить сразу после того, как они кодируют. Это приводит к более быстрым петлям обратной связи, меньшим количеством контекстов и большим импульсом. «Отчет о состоянии разработки приложений 2024 года» показывает, что почти в три раза больше организаций переходят от монолитов к микросервисам, чем наоборот, что делает эту возможность параллельного тестирования еще более критичной.
Качество: Тестирование перед температурой больше не ограничивается модульными тестами или высмеиваемыми зависимостями. Разработчики могут провести реалистичную интеграцию и сквозные тестирование (E2E) против общего базового уровня, вызывая проблемы гораздо раньше в цикле. Это резко уменьшает время, потраченное на отладку, «кто сломал постановку» до нуля.
Расходы: Этот подход гораздо более рентабельен, чем дублирование всей среды. Вы только дублируете услуги, которые изменились, делясь остальной частью стека. Это масштабируемое решение, которое не «привлекает внимание финансового директора». «Обследование состояния облачной стратегии Hashicorp» показало, что 91% организаций сообщают, что расходы на облачные данные потратили впустую, несмотря на то, что на 66% увеличиваются инвестиции в инфраструктуру.
Оперативная простота: Оперативное бремя управления хрупкой, всегда на основе среда значительно снижается. Очистка временных ресурсов может быть автоматизирована, так как они связаны с жизненным циклом песочницы.
Этот сдвиг остался при тестировании, включенный более умной моделью инфраструктуры, является ключом к разблокировке истинного значения архитектуры микросервисов: независимое, непрерывное развертывание. Речь идет о расширении возможностей команд работать параллельно и двигаться со скоростью, которую требования бизнеса, не жертвуя стабильностью или качеством.
Заключение
Слишком долго мы сосредоточились на оптимизации неправильной части жизненного цикла программного обеспечения. В то время как CI/CD имеет решающее значение, пришло время заглянуть за пределы трубопровода и обратиться к новому узкому месту в нашей инфраструктуре. Преобразуя общую стадирующую среду из однородно-блокнота в многопользовательную динамическую платформу, команды могут устранить трение, ускорить выпуска и восстановить их производительность.
Организации, стремящиеся реализовать это преобразование, могут изучить решения, такие как Signadot, которые предоставляют собственные песочницы Kubernetes, которые позволяют тестировать этот разработчик в Канарском стиле без сложности создания систем настраиваемой инфраструктуры.
Signadot-это платформа для тестирования Kubernetes для микросервисов. Используя Signadot, инженерные команды «сдвигаются налево», чтобы выяснить проблемы раньше и повысить доверие. Узнайте больше новейших из Signadot Trending Stories youtube.com/thenewstack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Арджун Айер, генеральный директор Signadot, является опытным экспертом в облачной местной области с глубокой страстью к улучшению опыта разработчика. У Арджуна хвастается более чем 25-летним опытом работы в отрасли, есть богатая история разработки программного обеспечения для интернет-масштаба и … Подробнее от Arjun Iyer