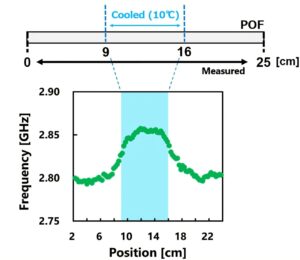
Порт спонсировал этот пост.
Инженеры по надежности сайта (SRES) и разработчики часто сталкиваются с проблемой балансировки скорости со стабильностью. По большей части разработчики, как правило, фокусируются на построении функций и кодирования, в то время как SREs гарантируют, что эти функции работают гладко в производстве. Но когда что -то сломается, линии размываются — и вот с чего начинаются проблемы.
Движение «Сдвиг слева» предлагает путь вперед. Это позволяет командам решать надежность и оперативные проблемы в начале процесса разработки. Деляя право собственности, команды могут сократить трение и лучше работать вместе.
SRE и разработчик отключаются
SRES несет ответственность за поддержание надежных систем, наблюдения за тем, чтобы выполнить время выполнения, управление инцидентами и обработку облачной инфраструктуры. Разработчики сосредоточены на написании кода и функций доставки. Однако эти роли часто перекрываются, создавая трение между ними.
Это напряжение возникает из -за смещенных приоритетов и отсутствия видимости в рабочих процессах друг друга. Разработчики определяют приоритеты функций доставки и могут пренебрегать требованиями производства до возникновения проблем. Хотя они создают приложения, они часто не чувствуют ответственности за свою надежность. И наоборот, SRES стремится поддерживать время безотказной работы, но может не иметь контекста в отношении недавних изменений применения. Эта динамика приводит к неэффективности, такой как:
Неполная видимость оставляет SRES неподготовленным во время инцидентов из -за отсутствия понимания недавних развертываний, зависимостей или изменений конфигурации. Фрагментированная собственность приводит к неясной подотчетности, что приводит к задержению в решении критических проблем. Отсутствие общих рамок препятствует общению и координации, особенно во время инцидентов высокого давления. Владельцы продуктов или заинтересованные стороны бизнеса могут оказывать дополнительное давление на SRES без четких процессов, что усугубляет и без того стрессовую ситуацию.
Хотя разработчики все чаще используют левое движение сдвига, сосредотачиваясь на производственных требованиях, безопасном кодировании и использовании инструментов ИИ для улучшения своих рабочих процессов, эти усилия недостаточны. Разработчики должны взять на себя полную ответственность за свои приложения, охватывая код и надежность. Кроме того, SRES и разработчики должны сотрудничать в общей структуре с единым источником истины для владения услугами, здоровьем и зависимостями. Этот фундамент позволяет более быстро, более эффективно рабочие процессы и смягчает отключения команды.
Шаг за шагом: переключение влево в управлении инцидентами
Рассмотрим сценарий, в котором инцидент с высокой чувствительностью происходит во время пикового движения. SRES может иметь все показатели инфраструктуры, но не имеют представления о недавних обновлениях или зависимостях приложений. С другой стороны, разработчики могут не иметь доступа к инструментам мониторинга производства, оставляя их слепыми к основной причине проблемы. Это отсутствие общей ответственности превращает управляемую проблему в длительный сбой.
Давайте рассмотрим пошаговое руководство по управлению инцидентом или отключением, чтобы продемонстрировать влияние сдвига влево.
1. Упреждающая профилактика
Предотвращение инцидентов начинается задолго до того, как они произойдут. Команды могут предпринять несколько проактивных шагов для обеспечения готовности производства:
Определите право собственности: Используйте унифицированный каталог услуг, чтобы установить четкое право собственности на каждую услугу, включая его зависимости, показатели здоровья и пути эскалации.
Автоматизируйте проверки готовности: Реализуйте автоматические проверки для производства готовности, такие как обеспечение надлежащей настройки наблюдения, проверка трубопроводов CI/CD и проверка устаревших зависимостей.
Установите активно: Установите оповещения о потенциальных проблемах, таких как увеличение частоты ошибок, медленное время отклика или аномалии в процессах развертывания. Эти предупреждения позволяют командам решать проблемы, прежде чем они обострятся. 2. Обнаружение и диагностику проблемы
Когда происходит инцидент, раскрытие и диагноз Swift имеют решающее значение:
Единая видимость: Команды используют централизованный портал для доступа к показателям в реальном времени, журналах и картах зависимости. Этот общий вид гарантирует, что у всех есть информация, необходимая для оценки проблемы.
Идентификация владения: Каталог услуг автоматически идентифицирует ответственную команду или индивидуума и уведомляет их через предварительные каналы связи, такие как Slack или команды.
Межфункциональное понимание: Как разработчики, так и SRE могут увидеть соответствующие подробности о недавних развертываниях, изменениях конфигурации и обновлениях приложений, что позволяет более быстрому анализу основной причины. 3. Координация ответа
С четкой владением и диагностическими данными, команда может сосредоточиться на решении проблемы:
Автоматизированные инцидентные каналы: Автоматизированный канал связи создается для объединения правильных заинтересованных сторон и обеспечения доступа к соответствующим инструментам и данным.
Самообслуживание исправления: Разработчики используют предопределенные рабочие процессы для решения этой проблемы, такие как отказ от неисправного развертывания, перезапуск услуг или масштабирования ресурсов. Эти действия могут быть выполнены непосредственно с портала, снижая зависимость от вмешательства SRE.
Протоколы эскалации: Если проблема требует специализированной экспертизы, SRES вступает для решения сложных проблем или обеспечения соблюдения оперативных стандартов. 4. Пост-инциденты улучшения
После разрешения инцидента команды сосредоточены на постоянном улучшении:
Анализ основной причины: Команды сотрудничают, чтобы понять, что пошло не так, и документируют их выводы в каталоге услуг.
Улучшения инструмента: Регулируйте инструменты мониторинга и автоматические рабочие процессы, чтобы предотвратить аналогичные проблемы в будущем.
Уточнение процесса: Включите обратную связь, чтобы улучшить процедуры реагирования, обучение и документацию.
В конечном счете, решение состоит в том, чтобы переопределить владение и предоставить каждому доступ к необходимым им инструментам. SRES должен сосредоточиться на установлении стандартов и автоматизации задач надежности, в то время как разработчики должны владеть своим приложениями в конечном итоге, включая время безотказной работы и здоровья.
Унифицированные каталоги обслуживания: ключ к переключению влево
Унифицированный каталог услуг может преодолеть разрыв. Это дает четкое представление о услугах, их владельцах и их зависимости. Это важная часть при внедрении подхода «сдвиг слева». Служив единственным источником истины, он предоставляет:
Четкое право собственности: Обеспечение того, чтобы у каждой службы были определенные владельцы и команда, ответственные за его здоровье и надежность.
Комплексная видимость: Предлагая информацию о зависимостях, конфигурациях и соблюдении стандартов готовности к производству.
Эффективное сотрудничество: Поддержка действий самообслуживания и автоматических рабочих процессов, чтобы обеспечить более быстрое, более эффективное разрешение инцидентов.
Хотя каталог услуг имеет решающее значение, он является частью более широкой экосистемы, которая включает в себя рабочие процессы самообслуживания, инструменты автоматизации инцидентов и сотрудничество. Вместе эти функции позволяют командам работать более эффективно и уверенно.
Настоящие победы с унифицированными инструментами
Команды, использующие Unified Service Catalogs, видят улучшения в проактивной профилактике и реактивном восстановлении. Вот более глубокий взгляд на преимущества:
Проактивное предотвращение инцидентов: Благодаря автоматическому отслеживанию соответствия команды могут выявлять и решать проблемы, прежде чем они обострятся. Например, команда может получать автоматические оповещения, когда приложение не соответствует критериям готовности к производству, таким как отсутствие настройки наблюдения или устаревшие зависимости. Обращаясь к этим пробелам перед выпуском, команда избегает отключений и обеспечивает более плавные запуска.
Более быстрое время восстановления: Во время инцидента, например, когда ключевая услуга снижается во время пикового трафик, разработчики могут быстро получить доступ к рабочим процессам самообслуживания, чтобы отменить изменения, перезапустить услуги или масштабные ресурсы. Вместо того, чтобы ждать вмешательства SRES, ответственный разработчик может следовать предопределенному пути исправления на портале — отскакивая недавние ресурсы развертывания или масштабирования одним щелчком. Это значительно снижает среднее время для восстановления (MTTR).
Улучшено сотрудничество: С четкой видимостью в собственности команды избегают путаницы во время ситуаций высокого давления. Например, когда происходит сбой, унифицированный портал немедленно идентифицирует владельца услуги и подтягивает соответствующие заинтересованные стороны через автоматизированные каналы пролета. Команды могут сосредоточиться на решении проблемы, а не на обсуждении, кто должен принять меры.
Представьте, что критический отключение происходит поздно ночью. Вместо того, чтобы пытаться выяснить, кто владеет затронутой службой, унифицированный портал автоматически создает выделенный канал Slack для инцидента, уведомляет владельца услуги и обеспечивает доступ к критическим показателям, журналам и картам зависимости. Через несколько минут команда может эффективно сотрудничать, чтобы решить проблему, резко сократив время простоя. Этот оптимизированный подход иллюстрирует способность перемещения влево: оснащение команд инструментами для действия быстро, уверенно и эффективно.
Новая модель владения
Смена левого поддерживает модель общей подотчетности. Разработчики владеют своими приложениями, включая надежность. SRES предоставляет руководство, инструменты и поддержку высокого уровня при необходимости. Этот баланс гарантирует, что все могут сосредоточиться на том, что они делают лучше всего.
Например, разработчики берут на себя инициативу в управлении ответом во время инцидента. Они используют инструменты, которые каталог услуг предоставляет для диагностики и исправления проблемы. SRES вступает только для сложных проблем или для обеспечения соблюдения стандартов. Этот подход уменьшает узкие места и дает возможность командам работать более эффективно.
Готовы переключиться налево?
Унифицированный каталог услуг может изменить то, как сотрудничают SRE и разработчики. Это способствует сотрудничеству, уменьшает узкие места и сохраняет надежные системы.
Поговорите с единомышленниками, которые также перемещаются налево в сообществе порта или посмотрите, как вы можете сдвинуться влево, используя живую демонстрацию порта.
Порт-это платформа для создания некодных, целостных, внутренних порталов разработчиков. Программный каталог порта охватывает микросервисы, ресурсы, пользовательские активы и подходит для любой модели данных, с показателями зрелости в контексте. Его порталы поддерживают любые действия по самообслуживанию разработчика и автоматизацию рабочего процесса. Узнайте больше последних из Port Trending Stories YouTube.com/ThenewStack Tech движется быстро, не пропустите эпизод. Подпишитесь на наш канал YouTube, чтобы транслировать все наши подкасты, интервью, демонстрации и многое другое. Группа подпишитесь с эскизом. Matar Peles является инженером по решениям в Port, платформе без кодов для внутренних порталов разработчиков. В своей ранней карьере Матар начался в Силах обороны Израиля как руководитель группы инфраструктуры крупных данных, где он предоставил управляемые решения больших данных … Подробнее от Матара Пелеса